INTRODUCTION
Any measurements, no matter how carefully they are performed, are accompanied by errors (errors), i.e. deviations of the measured values from their true value. This is explained by the fact that during the measurement process the conditions are continuously changing: the state external environment, measuring device and measured object, as well as the attention of the performer. Therefore, when measuring a quantity, its approximate value is always obtained, the accuracy of which must be assessed. Another task arises: to choose a device, conditions and methodology in order to perform measurements with a given accuracy. The theory of errors helps to solve these problems, which studies the laws of distribution of errors, establishes evaluation criteria and tolerances for measurement accuracy, methods for determining the most probable value of the quantity being determined, and rules for precalculating expected accuracies.
Measurement is the process of comparing a measured quantity with another known quantity taken as a unit of measurement.
All quantities we deal with are divided into measured and calculated. Measured a quantity is its approximate value, found by comparison with a homogeneous unit of measure. So, by sequentially laying the surveying tape in a given direction and counting the number of layings, an approximate value of the length of the section is found.
Calculated a quantity is its value determined from other measured quantities functionally related to it. For example, plot area rectangular shape is the product of its measured length and width.
To detect errors (gross errors) and increase the accuracy of the results, the same value is measured several times. According to accuracy, such measurements are divided into equal and unequal. Equal current
- homogeneous multiple results of measuring the same quantity, performed by the same device (or different devices of the same accuracy class), by the same method and number of steps, under identical conditions. Unequal
- measurements performed when the conditions of equal accuracy are not met.
When mathematically processing measurement results great importance has the number of measured quantities. For example, to get the value of each angle of a triangle, it is enough to measure only two of them - this will be necessary
number of quantities. In the general case, to solve any topographic-geodetic problem it is necessary to measure a certain minimum number of quantities that provide a solution to the problem. They are called the number of required quantities
or measurements. But in order to judge the quality of measurements, check their correctness and increase the accuracy of the result, the third angle of the triangle is also measured - excess
. Number of redundant quantities
(k
) is the difference between the number of all measured quantities ( P
) and the number of required quantities ( t
):
In topographic and geodetic practice, redundant measured quantities are mandatory. They make it possible to detect errors (inaccuracies) in measurements and calculations and increase the accuracy of the determined values.
By physical performance
measurements can be direct, indirect and remote.
Direct
measurements are the simplest and historically the first types of measurements, for example, measuring the lengths of lines with a surveyor's tape or tape measure.
Indirect
measurements are based on the use of certain mathematical relationships between the sought and directly measured quantities. For example, the area of a rectangle on the ground is determined by measuring the lengths of its sides.
Remote
measurements are based on the use of a series physical processes and phenomena and are usually associated with the use of modern technical means: light rangefinders, electronic tacheometers, phototheodolites, etc.
Measuring instruments used in topographic and geodetic production can be divided into three main classes :
When measuring the same quantity multiple times, slightly different results are obtained each time, both in absolute value and in sign, no matter how much experience the performer has and no matter what high-precision instruments he uses.
Errors are distinguished: gross, systematic and random.
Appearance rude
errors ( misses
) is associated with serious errors during measurement work. These errors are easily identified and eliminated as a result of measurement control.
Systematic errors
are included in each measurement result according to a strictly defined law. They are caused by the influence of the design of measuring instruments, errors in the calibration of their scales, wear, etc. ( instrumental errors)
or arise due to underestimation of measurement conditions and patterns of their changes, the approximation of some formulas, etc. ( methodological errors).
Systematic errors are divided into permanent
(constant in sign and magnitude) and variables
(changing their value from one dimension to another according to a certain law).
Such errors are determinable in advance and can be reduced to the necessary minimum by introducing appropriate amendments.
For example, the influence of the curvature of the Earth on the accuracy of determining vertical distances, the influence of air temperature and atmospheric pressure when determining the lengths of lines with light range finders or electronic total stations can be taken into account in advance, the influence of atmospheric refraction, etc. can be taken into account in advance.
If gross errors are avoided and systematic errors are eliminated, then the quality of measurements will be determined only random errors. These errors cannot be eliminated, but their behavior is subject to the laws of large numbers. They can be analyzed, controlled and reduced to the required minimum.
To reduce the influence of random errors on measurement results, they resort to multiple measurements, improve working conditions, select more advanced instruments and measurement methods, and carry out their careful production.
By comparing the series of random errors of equal-precision measurements, we can find that they have the following properties:
a) for a given type and measurement conditions, random errors cannot exceed a certain limit in absolute value;
b) errors that are small in absolute value appear more often than large ones;
c) positive errors appear as often as negative ones equal in absolute value;
d) the arithmetic mean of random errors of the same quantity tends to zero with an unlimited increase in the number of measurements.
The distribution of errors corresponding to the specified properties is called normal (Fig. 12.1).
Rice. 12.1. Gaussian random error bell curve
The difference between the result of measuring a certain quantity ( l) and its true meaning ( X) called absolute (true) error .
Δ = l - XIt is impossible to obtain the true (absolutely accurate) value of the measured quantity, even using the instruments itself. high precision and the most advanced measurement technique. Only in individual cases can the theoretical value of a quantity be known. The accumulation of errors leads to the formation of discrepancies between the measurement results and their actual values.
The difference between the sum of practically measured (or calculated) quantities and its theoretical value is called residual.
For example, the theoretical sum of angles in a plane triangle is equal to 180º, and the sum of the measured angles turned out to be equal to 180º02"; then the error in the sum of the measured angles will be +0º02". This error will be the angular discrepancy of the triangle.
The absolute error is not a complete indicator of the accuracy of the work performed. For example, if a certain line whose actual length is 1000 m, measured with a surveying tape with an error of 0.5 m, and the segment is 200 long m- with an error of 0.2 m, then, despite the fact that the absolute error of the first measurement is greater than the second, the first measurement was still performed with an accuracy twice as high. Therefore, the concept is introduced relative errors:
Ratio of the absolute error of the measured valueΔ to measured valuelcalled relative error.
Relative errors are always expressed as a fraction with a numerator equal to one (aliquot fraction). So, in the above example, the relative error of the first measurement is
and the second
Let some quantity with a true value X measured equally accurately n
times and the results were obtained: l 1
, l 2
, l 3
, …
li
(i = 1, 2, 3, … n), which is often called a series of dimensions. It is required to find the most reliable value of the measured quantity, which is called most likely
,
and evaluate the accuracy of the result.
In the theory of errors, the most probable value for a number of equally accurate measurement results is taken to be average
,
i.e.
 (12.1)
(12.1)
In the absence of systematic errors, the arithmetic average as the number of measurements increases indefinitely tends to the true value of the measured quantity.
To enhance the influence of larger errors on the result of assessing the accuracy of a number of measurements, use root mean square error
(UPC). If the true value of the measured quantity is known, and the systematic error is negligible, then the mean square error ( m
) of a separate result of equal-precision measurements is determined by the Gauss formula:
m =
 (12.2)
,
(12.2)
,
Where Δ i - true error.
In geodetic practice, the true value of the measured quantity is in most cases unknown in advance. Then the root mean square error of an individual measurement result is calculated from the most probable errors ( δ ) individual measurement results ( l i ); according to Bessel's formula:
m
=  (12.3)
(12.3)
Where are the most likely errors ( δ i ) are defined as the deviation of measurement results from the arithmetic mean
δ i = l i - µ
Often, next to the most probable value of a quantity, its root mean square error ( m), for example 70°05" ± 1". This means that the exact value of the angle may be greater or less than the specified one by 1". However, this minute cannot be added to or subtracted from the angle. It characterizes only the accuracy of obtaining results under given measurement conditions.
Analysis of the Gaussian normal distribution curve shows that with a sufficiently large number of measurements of the same quantity, the random measurement error can be:
It is unlikely that the random measurement error would be greater than triple the root mean square, so triple the mean square error is considered the maximum:
Δ prev = 3m
The maximum error is the value of a random error, the occurrence of which is unlikely under the given measurement conditions.
The mean square error equal to
Δpre = 2.5m ,
With an error probability of about 1%.
Square of the mean square error of the algebraic sum of the argument equal to the sum squares of the mean square errors of the terms
m S 2 = m 1 2+m 2 2+m 3 2 + .....+ m n 2
In the special case when m 1 = m 2 = m 3 = m n= m to determine the root mean square error of the arithmetic mean, use the formula
m S =
The root mean square error of the algebraic sum of equal precision measurements is several times greater than the root mean square error of one term.
Example.
If 9 angles are measured with a 30-second theodolite, then the root mean square error of angular measurements will be
m angle = 30 " = ±1.5"
Mean square error of arithmetic mean
(accuracy of determining the arithmetic mean)
For example, it is required to determine the angle with an accuracy of ± 15 seconds in the presence of a 30-second theodolite.
![]()
If you measure the angle 4 times ( n) and determine the arithmetic mean, then the root mean square error of the arithmetic mean ( mµ ) will be ± 15 seconds.
Root mean square error of the arithmetic mean ( m µ ) shows to what extent the influence of random errors during repeated measurements is reduced.
Example
The length of one line was measured 5 times.
Based on the measurement results, calculate: the most probable value of its length L(average); most probable errors (deviations from the arithmetic mean); root mean square error of one measurement m; accuracy of determining the arithmetic mean mµ, and the most probable value of the line length taking into account the root-mean-square error of the arithmetic mean ( L).
Processing distance measurement results (example)
Table 12.1.
Measurement number |
Measurement result, |
Most likely errors di, cm |
Square of the most probable error, cm 2 |
Characteristic |
|---|---|---|---|---|
m=±=±19 cm |
||||
Σ di = 0 |
[Σ di]2 = 1446 |
L= (980.65 ±0.08) m |
In case of unequal measurements, when the results of each measurement cannot be considered equally reliable, it is no longer possible to get by with the determination of a simple arithmetic average. In such cases, the merit (or reliability) of each measurement result is taken into account.
The value of measurement results is expressed by a certain number called the weight of this measurement.
. Obviously, the arithmetic average will have more weight compared to a single measurement, and measurements made using a more advanced and accurate device will have a greater degree of confidence than the same measurements made with a less accurate device.
Since the measurement conditions determine different values of the mean square error, the latter is usually taken as basics for assessing weight values,
measurements taken. In this case, the weights of the measurement results are taken inversely proportional to the squares of their corresponding mean square errors
.
So, if we denote by R And R measurement weights having root mean square errors, respectively m And µ
, then we can write the proportionality relation:
For example, if µ root mean square error of the arithmetic mean, and m- respectively, one dimension, then, as follows from
can be written:

i.e. the weight of the arithmetic average in n times the weight of a single measurement.
Similarly, it can be established that the weight of an angular measurement made by a 15-second theodolite is four times greater than the weight of an angular measurement made by a 30-second instrument.
In practical calculations, the weight of one value is usually taken as one and, under this condition, the weights of the remaining dimensions are calculated. So, in the last example, if we take the weight of the result of an angular measurement with a 30-second theodolite as R= 1, then the weight value of the measurement result with a 15-second theodolite will be R = 4.
All materials of geodetic measurements consist of field documentation, as well as documentation of computational and graphic work. Many years of experience in producing geodetic measurements and processing them allowed us to develop rules for maintaining this documentation.
Field documents include materials from verification of geodetic instruments, measurement logs and forms special form, outlines, picket magazines. All field documentation is considered valid only in the original. It is compiled in a single copy and, in case of loss, can only be restored by repeated measurements, which is almost not always possible.
The rules for keeping field journals are as follows.
1. Field journals should be filled out carefully; all numbers and letters should be written down clearly and legibly.
2. Correction of numbers and their erasure, as well as writing numbers by numbers are not allowed.
3. Erroneous recordings of readings are crossed out with one line and “erroneous” or “misprint” is indicated on the right, and correct results are inscribed at the top.
4. All entries in the journals are made with a simple pencil of medium hardness, ink or ballpoint pen; The use of chemical or colored pencils for this is not recommended.
5. When performing each type of geodetic survey, recordings of measurement results are made in appropriate journals of the established form. Before work begins, the pages of the logs are numbered and their number is certified by the work manager.
6. During field work, pages with rejected measurement results are crossed out diagonally with one line, the reason for the rejection and the number of the page containing the results of repeated measurements are indicated.
7. In each journal, on the title page, fill out information about the geodetic instrument (brand, number, mean square measurement error), record the date and time of observations, weather conditions (weather, visibility, etc.), names of performers, provide the necessary diagrams, formulas and notes.
8. The log must be filled out in such a way that another performer who is not involved in field work can accurately perform subsequent processing of measurement results. When filling out field journals, you should adhere to the following recording forms:
a) numbers in columns are written so that all digits of the corresponding digits are located one below the other without offset.
b) all results of measurements performed with equal accuracy are recorded with the same number decimal places.
Example
356.24 and 205.60 m - correct,
356.24 and 205.6 m - incorrect;
c) the values of minutes and seconds during angular measurements and calculations are always written as a two-digit number.
Example
127°07"05 "
, not 127º7"5 "
;
d) in the numerical values of the measurement results, write down such a number of digits that allows you to obtain the reading device of the corresponding measuring instrument. For example, if the length of a line is measured with a tape measure with millimeter divisions and the reading is carried out with an accuracy of 1 mm, then the reading should be written as 27.400 m, not 27.4 m. Or if the goniometer can only count whole minutes, then the reading should be written as 47º00 " , not 47º or 47º00"00".
Processing of measurement results begins after checking all field materials. In this case, one should adhere to the rules and techniques developed by practice, the observance of which facilitates the work of the calculator and allows him to rationally use computer technology and auxiliary tools.
1. Before starting to process the results of geodetic measurements, a detailed computational scheme should be developed, which indicates the sequence of actions that allows you to obtain the desired result in the simplest and fastest way.
2. Taking into account the volume of computational work, choose the most optimal means and methods of calculations that require least cost while ensuring the required accuracy.
3. The accuracy of calculation results cannot be higher than the accuracy of measurements. Therefore, sufficient, but not excessive, accuracy of computational actions should be specified in advance.
4. When making calculations, you cannot use drafts, since rewriting digital material takes a lot of time and is often accompanied by errors.
5. To record the results of calculations, it is recommended to use special diagrams, forms and sheets that determine the order of calculations and provide intermediate and general control.
6. Without control, the calculation cannot be considered complete. Control can be performed using a different move (method) for solving the problem or performing repeated calculations by another performer (in “two hands”).
7. Calculations always end with the determination of errors and their mandatory comparison with the tolerances provided for by the relevant instructions.
8. When performing computational work, special requirements are placed on the accuracy and clarity of recording numbers in computational forms, since negligence in entries leads to errors.
As in field journals, when recording columns of numbers in computational schemes, digits of the same digits should be placed one below the other. In this case, the fractional part of the number is separated by a comma; It is advisable to write multi-digit numbers at intervals, for example: 2 560 129.13. Records of calculations should be kept only in ink and in roman font; Carefully cross out erroneous results and write the corrected values at the top.
When processing measurement materials, you should know with what accuracy the calculation results must be obtained so as not to operate with an excessive number of characters; if the final result of the calculation is obtained with a large number characters than necessary, then the numbers are rounded.
Round number up n signs - means to preserve the first n significant figures.
The significant digits of a number are all of its digits from the first non-zero digit on the left to the last recorded digit on the right. In this case, zeros on the right are not considered significant digits if they replace unknown digits or are placed instead of other digits when rounding a given number.
For example, the number 0.027 has two significant figures, and the number 139.030 has six significant figures.
When rounding numbers, you should adhere to the following rules.
1. If the first of the discarded digits (counting from left to right) is less than 5, then the last remaining digit is kept unchanged.
For example, the number 145.873 after rounding to five significant figures is 145.87.
2. If the first of the discarded digits is greater than 5, then the last remaining digit is increased by one.
For example, the number 73.5672 after rounding it to four significant figures becomes 73.57.
3. If the last digit of the rounded number is 5 and it must be discarded, then the preceding digit in the number is increased by one only if it is odd (even digit rule).
For example, the numbers 45.175 and 81.325 after rounding to 0.01 would be 45.18 and 81.32, respectively.
The value of graphic materials (plans, maps and profiles), which are the end result of geodetic surveys, is largely determined not only by the accuracy of field measurements and the correctness of their computational processing, but also by the quality of graphic execution. Graphic work must be performed using carefully tested drawing tools: rulers, triangles, geodetic protractors, measuring compasses, sharpened pencils (T and TM), etc. The organization of the workplace has a great influence on the quality and productivity of drawing work. Drawing work must be performed on sheets of high-quality drawing paper, mounted on a flat table or on a special drawing board. The original pencil drawing of the graphic document, after careful checking and correction, is drawn up in ink in accordance with the established conventions.
Questions and tasks for self-control
UDC 543.08+543.422.7
PREDICTION OF PHOTOMETRY ERRORS USING THE LAW OF ERROR ACCUMULATION AND THE MONTE CARLO METHOD
IN AND. Golovanov, EM Danilina
In a computational experiment, using a combination of the error propagation law and the Monte Carlo method, the influence of solution preparation errors, blank experiment errors and transmittance measurement errors on the metrological characteristics of photometric analysis was investigated. It was found that the results of error prediction by analytical and statistical methods are mutually consistent. It is shown that a feature of the Monte Carlo method is the ability to predict the distribution law of errors in photometry. Using the example of a routine analysis scenario, the influence of heteroscedasticity of the scatter along the calibration graph on the quality of the analysis is considered.
Key words: photometric analysis, error accumulation law, calibration graph, metrological characteristics, Monte Carlo method, stochastic modeling.
Introduction
Prediction of errors in photometric analysis is mainly based on the use of the law of accumulation of errors (LOA). For the occasion linear shape law of light absorption: - 1§T = A = b1c, ZNO is usually written by the equation:
8A _ 8C _ 0.434-10^
A '8T-
In this case, the standard deviation of the transmittance measurement is assumed to be constant over the entire dynamic range of the photometer. At the same time, as noted in, in addition to instrumental errors, the accuracy of the analysis is affected by the error of the blank experiment, the error in setting the instrument scale limits, the cuvette error, chemical factors, and the error in setting the analytical wavelength. These factors are considered the main sources of error in the analysis result. Contributions to the accumulated error in the accuracy of preparing calibration solutions are usually neglected.
From this we see that equation (1) does not have significant predictive power, since it takes into account the influence of only one factor. In addition, equation (1) is a consequence of the approximate expansion of the light absorption law into a Taylor series. This raises the question of its accuracy, due to the neglect of terms of the expansion above the first order. Mathematical analysis of decomposition residues is associated with computational difficulties and in practice chemical analysis does not apply.
The purpose of this work is to study the possibility of using the Monte Carlo method (statistical testing method) as an independent method for studying and predicting the accumulation of errors in photometric analysis, complementing and deepening the capabilities of ZNO.
Theoretical part
In this work, we will assume that the final random error of the calibration function is caused not only by instrumental errors in measuring optical density, but also by errors in setting the instrument scale to 0 and 100% transmittance (the error of
extensive experience), as well as errors in the preparation of calibration solutions. We neglect the other sources of errors mentioned above. Then we rewrite the equation of the Bouguer-Lambert-Beer law in a form convenient for further construction:
Ay = ks" + A
In this equation, c51 is the concentration of the head standard solution of the colored substance, aliquots (Va) of which are diluted in flasks with a nominal volume Vd to obtain a calibration series of solutions, Ai is the optical density of the blank solution. Since during photometry the optical density of the test solutions is measured relative to a blank solution, i.e. Ay is taken as a conventional zero, then Ay = 0. (Note that the optical density value measured in this case can be called the conventional extinction.) In equation (2) the dimensionless quantity c" has the meaning of the concentration of the working solution, expressed in units of the concentration of the head standard. We will call the coefficient k the extinction of the standard, since Ag1 = e1c81 with c" = 1.
Let us apply the operator of the law of accumulation of random errors to expression (2), assuming Vа, Vd and Ау to be random variables. We get:
Another independent random variable that affects the spread of A values is the degree of transmission, since
A = -1§T, (4)
Therefore, we add one more term to the variances on the left side of equation (3):
52а=(0.434-10а)Ч+8Іьі +
In this final recording of the law of accumulation of errors, the absolute standard deviations of T, Ay and Ud are constant, and for Va the relative standard error is constant.
When constructing a stochastic model of the calibration function based on the Monte Carlo method, we assume that the possible values x* of the random variables T, Ay Ua and Vd are distributed according to the normal law. According to the Monte Carlo principle, we will play out possible values using the inverse function method:
X; =M(x1) + р-1(г])-вХ|, (6)
where M(x) is the mathematical expectation (real value) of the variable, ¥(r^) is the Laplace-Gaussian function, μ is the possible values uniformly distributed over the interval (0,1) random variable I, i.e. random numbers, zx - standard deviation of the corresponding variable, \ = 1...m - serial number of the independent random variable. After substituting expression (6) into equations (4) and (2) we have:
A" = -18Хі=-1810-а + Р-1(г])8т,
where A" = "k-+ x2
Calculations using equation (7) return a separate implementation of the calibration function, i.e. dependence of A" on the mathematical expectation M(c") (nominal value c"). Therefore, entry (7) is an analytical expression of a random function. The cross sections of this function are obtained by repeatedly playing random numbers at each point of the calibration dependence. Sample population realizations are processed by methods of mathematical statistics in order to estimate general calibration parameters and test hypotheses about the properties of the general population.
It is obvious that the two approaches we are considering to the problem of predicting metrological characteristics in photometry - based on ZNO, on the one hand, and based on the Monte Carlo method, on the other, should complement each other. In particular, from equation (5) it is possible to obtain the result with a much smaller amount of calculations compared to (7), as well as ranking
rank random variables according to the significance of their contributions to the resulting error. Ranking allows you to abandon the screening experiment in statistical tests and a priori exclude insignificant variables from consideration. Equation (5) is easy to analyze mathematically in order to judge the nature of the contributions of factors to the total variance. Partial contributions of factors can be divided into those independent of A, or increasing with increasing optical density. Therefore, sA as a function of A must be a monotonically increasing dependence without a minimum. When approximating experimental data by equation (5), partial contributions of the same nature will be mixed, for example, the experimental error may be mixed with the error of the blank experiment. On the other hand, when statistically testing the model using the Monte Carlo method, it is possible to identify such important properties of the calibration graph as the law(s) of error distribution, as well as to evaluate the speed of convergence of sample estimates to the general ones. Such an analysis is not possible based on cancer.
Description of the computational experiment
When constructing a calibration simulation model, we assume that the calibration series of solutions is prepared in volumetric flasks with a nominal capacity of 50 ml and a maximum error of +0.05 ml. Add from 1 to 17 ml of stock standard solution to a series of flasks with a pipetting error of > 1%. Volume measurement errors were assessed using the reference book. Aliquots are added in uniform increments of 1 ml. There are a total of 17 solutions in the series, the optical density of which covers the range from 0.1 to 1.7 units. Then in equation (2) the coefficient k = 5. The error of the blank experiment is taken at the level of 0.01 units. optical density. Errors in measuring the degree of transmittance, according to , depend only on the class of the device and are in the range from 0.1 to 0.5% T.
To better relate the conditions of the computational experiment to the laboratory experiment, we used data on the reproducibility of measurements of the optical densities of K2Cr2O7 solutions in the presence of 0.05 M H2S04 on an SF-26 spectrophotometer. The authors approximate the experimental data in the interval A = 0.1... 1.5 with a parabolic equation:
sBOCn*103 =7.9-3.53A + 10.3A2. (8)
We managed to fit the calculations using the theoretical equation (5) to the calculations using the empirical equation (8) using Newton's optimization method. We found that equation (5) satisfactorily describes the experiment at s(T) = 0.12%, s(Abi) = 0.007 and s r(Va) = 1.1%.
The independent error estimates given in the previous paragraph are in good agreement with those found during the fitting. For calculations according to equation (7), a program was created in the form of a MS Excel spreadsheet sheet. The most significant feature of our Excel program is the use of the expression NORMSINV(RAND()) to generate normally distributed errors, see equation (6). In the specialized literature on statistical calculations in Excel, the “Random Number Generation” utility is described in detail, which in many cases is preferably replaced with functions like NORMSINV(RAND()). This replacement is especially convenient when creating your own programs for Monte Carlo simulation.
Results and its discussion
Before proceeding with statistical tests, let us estimate the contributions of the terms on the left side of equation (5) to the total dispersion of optical density. To do this, each term is normalized to the total variance. Calculations were performed with s(T) = 0.12%, s(Aw) = 0.007, Sr(Va)=l.l% and s(Vfi) = 0.05. The calculation results are shown in Fig. 1. We see that contributions to the total variance of measurement errors Vfl can be neglected.
While the contributions of another value, which affects the errors in preparing solutions, Va
dominate in the optical density range 0.8__1.2. However, this conclusion is not general
nature, since when measuring on a photometer with s(T) = 0.5%, the calibration errors, according to calculations, are determined mainly by the spread of Ay and the spread of T. In Fig. Figure 2 compares the relative errors in measurements of optical densities predicted based on ZNO (solid line) and the Monte Carlo method (symbols). In statistical tests, the curve
errors were reconstructed from 100 realizations of the calibration dependence (1700 optical density values). We see that both forecasts are mutually consistent. The points are evenly grouped around the theoretical curve. However, even with such rather impressive statistical material, complete convergence is not observed. In any case, the scatter does not allow us to identify the approximate nature of cancer, see introduction.
0 0.4 0.8 1.2 1.6
Rice. 1. Weighted contributions of the terms of equation (5) to the variance A: 1 - for Ay; 2 - for Ua; 3 - for T; 4 - for
Rice. 2. Error curve of the calibration graph
From the theory of mathematical statistics it is known that when performing interval estimation of the mathematical expectation of a random variable, the reliability of the estimation increases if the distribution law for this quantity is known. In addition, in the case of a normal distribution, the estimation is the most efficient. Therefore, studying the law of distribution of errors in the calibration graph is an important task. In such a study, first of all, the hypothesis of the normality of the scatter of optical densities at individual points of the graph is tested.
A simple way to test the main hypothesis is to calculate the skewness coefficients (a) and kurtosis coefficients (e) of empirical distributions, as well as their comparison with criterion values. The reliability of statistical conclusions increases as the volume of sample data increases. In Fig. Figure 3 shows the sequence of coefficients for 17 sections of the calibration function. The coefficients are calculated based on the results of 100 tests at each point. The critical values of the coefficients for our example are |a| = 0.72 and |e| = 0.23.
From Fig. 3 we can conclude that the scattering of values at the points of the graph, in general, is not
contradicts the normality hypothesis, since the sequences of coefficients have almost no preferred direction. The coefficients are randomly localized near zero line(shown in dotted line). For a normal distribution, as is known, the mathematical expectation of the skewness coefficient and the kurtosis coefficient is zero. Judging by the fact that for all sections the asymmetry coefficients are significantly lower than the critical value, we can confidently speak about the symmetry of the distribution of calibration errors. It is possible that the error distributions are slightly skewed compared to the normal distribution curve. This conclusion follows from what is observed in Fig. 3 small polo-
Rice. 3. Kurtosis coefficients (1) and asymmetry coefficients (2) at the points of the calibration graph
resident shift of the central line of dispersion of kurtosis coefficients. Thus, from studying the model of the generalized calibration function of photometric analysis using the Monte Carlo method (2), we can conclude that the distribution of calibration errors is close to normal. Therefore, calculations of confidence intervals for the results of photometric analysis using Student coefficients can be considered quite justified.
When performing stochastic modeling, the speed of convergence of sample error curves (see Fig. 2) to the mathematical expectation of the curve was assessed. For the mathematical expectation of the error curve we will take the curve calculated from the ZNO. The closeness of the results of statistical tests with different numbers of calibration implementations n to the theoretical curve will be assessed by the uncertainty coefficient 1 - R2. This coefficient characterizes the proportion of variation in the sample that could not be described theoretically. We have established that the dependence of the uncertainty coefficient on the number of realizations of the calibration function can be described by the empirical equation I - K2 = -2.3n-1 + 1.6n~/a -0.1. From the equation we find that at n = 213 we should expect almost complete coincidence of the theoretical and empirical error curves. Thus, a consistent assessment of the errors of photometric analysis can only be obtained on a fairly large statistical material.
Let us consider the capabilities of the statistical test method for predicting the results of regression analysis of the calibration graph and using the graph in determining the concentrations of photometered solutions. To do this, we will select the measurement situation of routine analysis as a scenario. The graph is plotted using single measurements of the optical densities of a series of standard solutions. The concentration of the analyzed solution is found from the graph based on 3-4 results of parallel measurements. When choosing a regression model, it should be taken into account that the spread of optical densities at different points of the calibration graph is not the same, see equation (8). In the case of heteroekedastic scatter, it is recommended to use the weighted least squares (WLS) scheme. However, in the literature we have not found clear indications of the reasons why the classical OLS scheme, one of the conditions of applicability of which is the requirement of homoscedasticity of the scatter, is less preferable. These reasons can be established by processing the same statistical material obtained by the Monte Carlo method according to the routine analysis scenario, with two variants of OLS - classical and weighted.
As a result of regression analysis of only one implementation of the calibration function, the following least squares estimates were obtained: k = 4.979 with Bk = 0.023. When assessing the same characteristics of the VMNC, we obtain k = 5.000 with Bk = 0.016. Regressions were reconstructed using 17 standard solutions. The concentrations in the calibration series increased in arithmetic progression, and the optical densities changed equally uniformly in the range from 0.1 to 1.7 units. In the case of VMNC, the statistical weights of the points of the calibration graph were found using the variances calculated according to equation (5).
The variances of estimates for both methods are statistically indistinguishable according to Fisher's test at a 1% significance level. However, at the same level of significance, the OLS estimate of k differs from the VMLS estimate according to the 1;-criterion. The OLS estimate of the coefficient of the calibration graph is shifted relative to the actual value M(k) = 5.000, judging by the test at a 5% significance level. Whereas weighted OLS gives an estimate that does not contain systematic error.
Now let’s find out how neglecting heteroscedasticity can affect the quality of chemical analysis. The table shows the results of a simulation experiment on the analysis of 17 control samples of a colored substance with different concentrations. Moreover, each analytical series included four solutions, i.e. For each sample, four parallel determinations were performed. To process the results, two different calibration dependencies were used: one was restored by a simple least squares method, and the second by a weighted one. We believe that control solutions were prepared for analysis in the same way as calibration solutions.
From the table we see that real values the concentrations of control solutions both in the case of VMNC and in the case of MNC do not fall outside the confidence intervals, i.e., the analysis results do not contain significant systematic errors. The maximum errors of both methods are not statistically different, in other words, both estimates
Comparing the results of determining concentrations has the same effectiveness. From-
control solutions using two methods, it can be concluded that when
In routine analyses, the use of a simple unweighted OLS design is quite justified. The use of VMNC is preferable if the research task is only the determination of molar extinction. On the other hand, it should be borne in mind that our conclusions are statistical in nature. It is likely that with an increase in the number of parallel determinations, the hypothesis about the unbiasedness of OLS estimates of concentrations will not find confirmation, even if the systematic errors are insignificant from a practical point of view.
What we have discovered is sufficient high quality analysis based on a simple classical least squares scheme seems especially unexpected if we take into account the fact that very strong heteroskedasticity is observed in the optical density range 0.1 h - 1.7. The degree of data heterogeneity can be judged by the weighting function, which is well approximated by the polynomial w = 0.057A2 - 0.193A + 0.173. From this equation it follows that at the extreme points of the calibration the statistical weights differ by more than 20 times. However, let us pay attention to the fact that the calibration functions were restored using 17 points on the graph, whereas during the analysis only 4 parallel determinations were performed. Therefore, the significant difference we discovered between the LLS and VMLS calibration functions and the insignificant difference in the results of the analysis using these functions can be explained by the significantly different number of degrees of freedom that were available when constructing statistical conclusions.
Conclusion
1. A new approach to stochastic modeling in photometric analysis is proposed based on the Monte Carlo method and the law of error accumulation using the Excel spreadsheet processor.
2. Based on 100 implementations of the calibration dependence, it is shown that the prediction of errors by the analytical and statistical methods are mutually consistent.
3. The coefficients of asymmetry and kurtosis along the calibration graph were studied. It was found that variations in calibration errors obey a distribution law close to normal.
4. The influence of heteroskedasticity in the scatter of optical densities during calibration on the quality of analysis is considered. It was found that in routine analyses, the use of a simple unweighted OLS scheme does not lead to a noticeable decrease in the accuracy of the analysis results.
Literature
1. Bernstein, I.Ya. Spectrophotometric analysis in organic chemistry / I.Ya. Bernstein, Yu.L. Kaminsky. - L.: Chemistry, 1986. - 200 p.
2. Bulatov, M.I. Practical guide on photometric methods of analysis / M.I. Bulatov, I.P. Kalinkin. - L.: Chemistry, 1986. - 432 p.
3. Gmurman, V.E. Probability theory and mathematical statistics / V.E. Gmurman. - M.: Higher School, 1977. - 470 p.
No. s", s", found (P = 95%)
n/a given by MNK VMNK
1 0.020 0.021±0.002 0.021±0.002
2 0.040 0.041±0.001 0.041±0.001
3 0.060 0.061±0.003 0.061±0.003
4 0.080 0.080±0.004 0.080±0.004
5 0.100 0.098±0.004 0.098±0.004
6 0.120 0.122±0.006 0.121±0.006
7 0.140 0.140±0.006 0.139±0.006
8 0.160 0.163±0.003 0.162±0.003
9 0.180 0.181±0.006 0.180±0.006
10 0.200 0.201±0.002 0.200±0.002
11 0.220 0.219±0.008 0.218±0.008
12 0.240 0.242±0.002 0.241±0.002
13 0.260 0.262±0.008 0.261±0.008
14 0.280 0.281±0.010 0.280±0.010
15 0.300 0.307±0.015 0.306±0.015
16 0.320 0.325±0.013 0.323±0.013
17 0.340 0.340±0.026 0.339±0.026
4. Pravdin, P. V. Laboratory instruments and equipment made of glass / P.V. Pravdin. - M.: Chemistry, 1988.-336 p.
5. Makarova, N.V. Statistics in Excel / N.V. Makarova, V.Ya. Trofimets. - M.: Finance and Statistics, 2002. - 368 p.
PREDICTION OF ERRORS IN PHOTOMETRY WITH THE USE OF ACCUMULATION OF ERRORS LAW AND MONTE CARLO METHOD
During computing experiment, in combination of the accumulation of errors law and Monte Carlo method, the influence of solution-making errors, blank experiment errors and optical transmission measurement errors upon metrological performance of photometrical analysis has been studied. It has been shown that the results of prediction by analytical and statistical methods are interconsistent. The unique feature of Monte Carlo method has been found to enable prediction of the accumulation of errors law in photometry. For the version of routine analysis the influence of heteroscedasticity of dispersion along calibration curve upon analysis quality has been studied.
Keywords: photometric analysis, accumulation of errors law, calibration curve, metrological performance, Monte Carlo method, stochastic modeling.
Golovanov Vladimir Ivanovich - Dr. Sc. (Chemistry), Professor, Head of the Analytical Chemistry Subdepartment, South Ural State University.
Golovanov Vladimir Ivanovich - Doctor of Chemical Sciences, Professor, Head of the Department of Analytical Chemistry, South Ural State University.
Email: [email protected]
Danilina Elena Ivanovna - PhD (Chemistry), Associate Professor, Analytical Chemistry Subdepartment, South Ural State University.
Danilina Elena Ivanovna - Candidate of Chemical Sciences, Associate Professor, Department of Analytical Chemistry, South Ural State University.
By measurement error we mean the totality of all measurement errors.
Measurement errors can be classified into the following types:
Absolute and relative,
Positive and negative,
Constant and proportional,
Random and systematic,
Absolute mistake A y) is defined as the difference of the following values:
A y = y i- y ist. y i - y,
Where: y i – single measurement result; y ist. – true measurement result; y– arithmetic mean value of the measurement result (hereinafter referred to as the mean).
Constant is called the absolute error, which does not depend on the value of the measured quantity ( y y).
Error proportional , if the named dependency exists. The nature of the measurement error (constant or proportional) is determined after special studies.
Relative error single measurement result ( IN y) is calculated as the ratio of the following quantities:
From this formula it follows that the magnitude of the relative error depends not only on the magnitude of the absolute error, but also on the value of the measured quantity. If the measured value remains unchanged ( y) the relative measurement error can be reduced only by reducing the absolute error ( A y). If the absolute measurement error is constant, the technique of increasing the value of the measured quantity can be used to reduce the relative measurement error.
The sign of the error (positive or negative) is determined by the difference between the single and the resulting (arithmetic mean) measurement result:
y i - y> 0 (error is positive );
y i - y< 0 (error is negative ).
Gross mistake measurement (miss) occurs when the measurement technique is violated. A measurement result containing a gross error usually differs significantly in magnitude from other results. The presence of gross measurement errors in the sample is established only by methods of mathematical statistics (with the number of measurement repetitions n>2). Get to know the methods for detecting gross errors yourself in.
TO random errors include errors that do not have a constant value and sign. Such errors arise under the influence of the following factors: unknown to the researcher; known but unregulated; constantly changing.
Random errors can only be assessed after measurements have been taken.
The following parameters can be a quantitative assessment of the modulus of the random measurement error: sample dispersion of single values and the average value; sample absolute standard deviations of single values and mean; sample relative standard deviations of single values and the mean; general dispersion of single values), respectively, etc.
Random measurement errors cannot be eliminated, they can only be reduced. One of the main ways to reduce the magnitude of random measurement error is to increase the number (sample size) of single measurements (increase the magnitude n). This is explained by the fact that the magnitude of random errors is inversely proportional to the magnitude n, For example:
 .
.
Systematic errors – these are errors with unchanged magnitude and sign or varying according to a known law. These errors are caused by constant factors. Systematic errors can be quantified, reduced, and even eliminated.
Systematic errors are classified into errors of types I, II and III.
TO systematic errorsItype refer to errors of known origin that can be estimated by calculation prior to measurement. These errors can be eliminated by introducing them into the measurement result in the form of corrections. An example of an error of this type is an error in the titrimetric determination of the volumetric concentration of a solution if the titrant was prepared at one temperature and the concentration was measured at another. Knowing the dependence of the titrant density on temperature, it is possible to calculate, before the measurement, the change in the volume concentration of the titrant associated with a change in its temperature, and this difference can be taken into account as a correction as a result of the measurement.
SystematicerrorsIItype– these are errors of known origin that can only be assessed during an experiment or as a result of special research. This type of errors includes instrumental (instrumental), reactive, reference, and other errors. Get to know the features of such errors yourself in .
Any device, when used in a measurement procedure, introduces its own instrument errors into the measurement result. Moreover, some of these errors are random, and the other part are systematic. Random instrument errors are not assessed separately; they are assessed in totality with all other random measurement errors.
Each instance of any device has its own personal systematic error. In order to evaluate this error, it is necessary to conduct special studies.
The most reliable way to assess type II instrument systematic error is to verify the operation of instruments against standards. For measuring glassware (pipette, burette, cylinders, etc.), a special procedure is carried out - calibration.
In practice, what is most often required is not to estimate, but to reduce or eliminate type II systematic error. The most common methods for reducing systematic errors are relativization and randomization methods.Discover these methods for yourself at .
TO mistakesIIItype include errors of unknown origin. These errors can be detected only after eliminating all systematic errors of types I and II.
TO other errors Let's include all other types of errors not discussed above (permissible, possible marginal errors, etc.).
The concept of possible limiting errors is used in cases of using measuring instruments and assumes the maximum possible value of the instrumental measurement error (the actual value of the error may be less than the value of the possible limiting error).
When using measuring instruments, you can calculate the possible maximum absolute (  ) or relative (
) or relative (  ) measurement error. So, for example, the possible maximum absolute measurement error is found as the sum of the possible maximum random (
) measurement error. So, for example, the possible maximum absolute measurement error is found as the sum of the possible maximum random (  ) and non-excluded systematic (
) and non-excluded systematic (  ) errors:
) errors:
 =
=
 +
+
For small samples ( n20) of an unknown population that obeys the normal distribution law, the random possible maximum measurement errors can be estimated as follows:
 =
=
 =
= ,
,
Where:
 – confidence interval for the corresponding probability R;
– confidence interval for the corresponding probability R;
 –quantile of Student's t-distribution for probability R and samples of n or with the number of degrees of freedom f
=
n
– 1.
–quantile of Student's t-distribution for probability R and samples of n or with the number of degrees of freedom f
=
n
– 1.
The absolute possible maximum measurement error in this case will be equal to:
 =
=
 +
+ .
.
If the measurement results do not obey the normal distribution law, then the errors are assessed using other formulas.
Determination of magnitude  depends on whether the measuring instrument has an accuracy class. If the measuring instrument does not have an accuracy class, then per size
depends on whether the measuring instrument has an accuracy class. If the measuring instrument does not have an accuracy class, then per size you can accept the minimum scale division price(or half of it) means of measurement. For a measuring instrument with a known accuracy class for the value
you can accept the minimum scale division price(or half of it) means of measurement. For a measuring instrument with a known accuracy class for the value  can be taken absolute permissible systematic error of the measuring instrument (
can be taken absolute permissible systematic error of the measuring instrument (  ):
):

 .
.
Magnitude  calculated based on the formulas given in table. 2.
calculated based on the formulas given in table. 2.
For many measuring instruments, the accuracy class is indicated in the form of numbers A10 n, Where A equals 1; 1.5; 2; 2.5; 4; 5; 6 and n equals 1; 0; -1; -2, etc., which show the value of the possible maximum permissible systematic error (E y , add.) and special signs indicating its type (relative, reduced, constant, proportional).
If the components of the absolute systematic error of the arithmetic mean measurement result are known (for example, instrument error, method error, etc.), then it can be estimated using the formula
 ,
,
Where: m– the number of components of the systematic error of the average measurement result;
k– coefficient determined by probability R and number m;
 – absolute systematic error of an individual component.
– absolute systematic error of an individual component.
Individual components of the error can be neglected if appropriate conditions are met.
table 2
Examples of designation of accuracy classes of measuring instruments
|
Class designation accuracy |
Calculation formula and value of the maximum permissible systematic error |
Characteristics of systematic error |
|
|
in the documentation |
on the measuring instrument |
||
|
|
The given permissible systematic error as a percentage of the nominal value of the measured value, which is determined by the type of scale of the measuring instrument |
||
|
|
The given permissible systematic error as a percentage of the length of the used scale of the measuring instrument (A) when obtaining single values of the measured quantity |
||
|
|
Constant relative permissible systematic error as a percentage of the obtained single value of the measured quantity |
||
|
c = 0,02; d = 0,01 |
Proportional relative permissible systematic error in fractions of the obtained single value of the measured value, which increases with increasing final value of the measurement range by a given measuring instrument ( y k) or decreasing the unit value of the measured quantity ( y i) |
||
Systematic errors can be neglected if the inequality holds
 0.8.
0.8.
In this case they accept

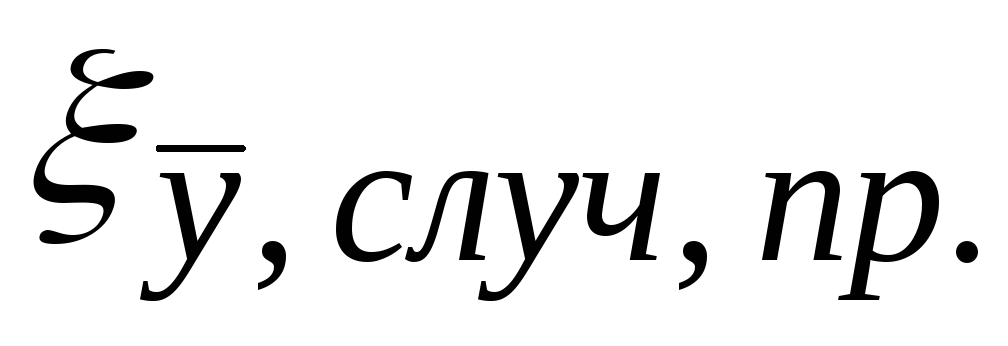

 .
.
Random errors can be neglected provided
 8.
8.
Ad hoc 
 .
.
To ensure that the overall measurement error is determined only by systematic errors, the number of repeated measurements is increased. The minimum number of repeated measurements required for this ( n min) can be calculated only with a known value of the population of individual results using the formula
 .
.
The assessment of measurement errors depends not only on the measurement conditions, but also on the type of measurement (direct or indirect).
The division of measurements into direct and indirect is quite arbitrary. In the future, under direct measurements We will understand measurements whose values are taken directly from experimental data, for example, read from the scale of an instrument (a well-known example of direct measurement is temperature measurement with a thermometer). TO indirect measurements we will include those whose results are obtained on the basis of a known relationship between the desired value and the values determined as a result of direct measurements. Wherein result indirect measurement received by calculation as function value , whose arguments are the results of direct measurements ( x 1 ,x 2 , …,x j,. ..., x k).
You need to know that the errors of indirect measurements are always greater than the errors of individual direct measurements.
Errors in indirect measurements are assessed according to the corresponding laws of error accumulation (with k2).
Law of accumulation of random errors indirect measurements looks like this:

 .
.
Law of accumulation of possible maximum absolute systematic errors indirect measurements are represented by the following dependencies:
 ;
;
 .
.
Law of accumulation of possible limiting relative systematic errors indirect measurements has the following form:
 ;
;
 .
.
In cases where the required value ( y) is calculated as a function of the results of several independent direct measurements of the form  , the law of accumulation of limiting relative systematic errors of indirect measurements takes a simpler form:
, the law of accumulation of limiting relative systematic errors of indirect measurements takes a simpler form:
 ;
;
 .
.
Errors and uncertainties in measurements determine their accuracy, reproducibility and correctness.
Accuracy the higher, the smaller the measurement error.
Reproducibility measurement results are improved by reducing random measurement errors.
Right the measurement result increases with a decrease in residual systematic measurement errors.
Learn more about the theory of measurement errors and their features yourself. I would like to draw your attention to the fact that modern forms of presenting the final measurement results necessarily require the inclusion of errors or measurement errors (secondary data). In this case, errors and measurement errors should be presented numbers, which contain no more than two significant figures .
What is "ERROR ACCUMULATION"? How to spell this word correctly. Concept and interpretation.
ACCUMULATION OF ERROR when solving algebraic equations numerically - the total influence of roundings made at individual steps of the computational process on the accuracy of the resulting linear algebraic solution. systems. The most common way to a priori estimate the total impact of rounding errors in numerical methods of linear algebra is the so-called scheme. reverse analysis. In application to solving a system of linear algebraic. equations, the inverse analysis scheme is as follows. The solution calculated by the direct method does not satisfy (1), but can be represented as an exact solution of the perturbed system. The quality of the direct method is assessed by the best a priori estimate, which can be given for the norms of the matrix and vector. Such “best” and so-called. respectively, the matrix and the vector of equivalent perturbation for the method M. If estimates for and are available, then theoretically the error of the approximate solution can be estimated by the inequality Here is the condition number of the matrix A, and the matrix norm in (3) is assumed to be subordinate to the vector norm. In reality, the estimate for is rarely known , and the main meaning of (2) is the ability to compare quality various methods. Below is the form of some typical estimates for the matrix For methods with orthogonal transformations and floating point arithmetic (in system (1) A and b are considered real) In this estimate - the relative accuracy of arithmetic. operations in a computer, is the Euclidean matrix norm, f(n) is a function of the form, where n is the order of the system. Exact values The C constants of the indicator k are determined by such details of the computational process as the method of rounding, the use of the operation of accumulating scalar products, etc. Most often, k = 1 or 3/2. In the case of Gaussian-type methods, the right side of estimate (4) also includes a factor that reflects the possibility of growth of the elements of the Ana matrix at intermediate steps of the method compared to the initial level (such growth is absent in orthogonal methods). To reduce the value, use various ways selection of the leading element, preventing the increase of matrix elements. For the square root method, which is usually used in the case of a positive definite matrix A, the strongest estimate is obtained. There are direct methods (Jordan, bordering, conjugate gradients), for which direct application of the inverse analysis scheme does not lead to effective estimates. In these cases, when studying N., other considerations are also applied (see -). Lit.: Givens W., "TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL", 1954, No. 1574; Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; Wilkinson J. stability in direct methods of linear algebra, M., 1969; by him, Computational foundations of linear algebra, M., 1977; Peters G., Wilkinson J. H., "Communes Assoc. Comput. Math.", 1975, v. 18, no. 1, p. 20-24; Crowden C. G., "J. Inst. Math, and Appl.", 1974, v. 14, no. 2, p. 131-40; Reid J.K., in: Large Sparse Sets of Linear Equations, L.-N.Y., 1971, p. 231 - 254; Ikramov Kh. D., "J. computational mathematics and mathematical physics", 1978, vol. 18, no. 3, p. 531-45. Kh. D. Ikramov. The problem of rounding or method error arises when solving problems where the solution is the result of a large number of sequentially performed arithmetic. operations. A significant part of such problems involves solving algebraic problems. problems, linear or nonlinear (see above). In turn, among algebraic problems The most common problems arise when approximating differential equations. These tasks have certain specific characteristics. peculiarities. The method of solving the problem occurs according to the same or more simple laws, which is the same as the N. point of computational error; N., p. method is examined when evaluating a method for solving a problem. When studying the accumulation of computational error, two approaches are distinguished. In the first case, it is believed that computational errors at each step are introduced in the most unfavorable way and a majorant estimate of the error is obtained. In the second case, it is believed that these errors are random with a certain distribution law. The nature of the problem depends on the problem being solved, the method of solution, and a number of other factors that at first glance may seem unimportant; This includes the form of recording numbers in a computer (fixed point or floating point), the order in which arithmetic is performed. operations, etc. For example, in the problem of calculating the sum of N numbers, the order in which the operations are performed is important. Let the calculations be performed on a floating point machine with t binary digits and all numbers lie within the limits. When directly calculated using the recurrent formula, the majorant error estimate is of the order of 2-tN. You can do it differently (see). When calculating pairwise sums (if N=2l+1 is odd) assume. Next, their pairwise sums are calculated, etc. After the steps of forming pairwise sums, a majorant estimate of the order error is obtained using the formulas. In typical problems, the quantities a m are calculated using formulas, in particular recurrent ones, or are entered sequentially into the computer's RAM; in these cases, the use of the described technique leads to an increase in the computer memory load. However, it is possible to organize the sequence of calculations so that loading random access memory will not exceed -log2N cells. When solving differential equations numerically, the following cases are possible. As the grid step h approaches zero, the error grows as where. Such methods of solving problems are classified as unstable. Their use is sporadic. character. Stable methods are characterized by an increase in error as The error of such methods is usually assessed as follows. An equation is constructed regarding the disturbance introduced either by rounding or by method errors and then the solution to this equation is examined (see,). In more difficult cases The method of equivalent perturbations is used (see , ), developed in relation to the problem of studying the accumulation of computational errors when solving differential equations (see , , ). Calculations using a certain calculation scheme with rounding are considered as calculations without rounding, but for an equation with perturbed coefficients. By comparing the solution of the original grid equation with the solution of the equation with perturbed coefficients, an error estimate is obtained. Considerable attention is paid to choosing a method with, if possible, lower values of q and A(h). With a fixed method for solving the problem, the calculation formulas can usually be converted to the form where (see , ). This is especially significant in the case of ordinary differential equations, where the number of steps in some cases turns out to be very large. The value (h) can grow greatly with increasing integration interval. Therefore, they try to use methods with a lower value of A(h) if possible. In the case of the Cauchy problem, the rounding error at each specific step in relation to subsequent steps can be considered as an error in the initial condition. Therefore, the infimum (h) depends on the characteristic of the divergence of close solutions of the differential equation defined by the variational equation. In the case of a numerical solution of an ordinary differential equation, the equation in variations has the form and therefore, when solving a problem on the interval (x 0 , X), one cannot count on the constant A(h) in the majorant estimate of the computational error being significantly better than Therefore, when solving this problem, one-step methods are most commonly used methods of the Runge-Kutta type or methods of the Adams type (see,), where the method is mainly determined by solving the equation in variations. For a number of methods, the main term of the method error accumulates according to a similar law, while the computational error accumulates much faster (see). Area of practice the applicability of such methods turns out to be significantly narrower. The accumulation of computational error significantly depends on the method used to solve the grid problem. For example, when solving grid boundary value problems corresponding to ordinary differential equations using shooting and sweeping methods, the linear problem has the character A(h)h-q, where q is the same. The values of A(h) for these methods may differ so much that in a certain situation one of the methods becomes inapplicable. When solving a grid boundary value problem for Laplace's equation by the shooting method, the problem has the character c 1/h, c>1, and in the case of the sweep method Ah-q. With a probabilistic approach to the study of rounding errors, in some cases they a priori assume some kind of error distribution law (see), in other cases they introduce a measure on the space of the problems under consideration and, based on this measure, obtain a law of rounding error distribution (see, ). With moderate accuracy in solving the problem, majorant and probabilistic approaches to assessing the accumulation of computational error usually give qualitatively the same results: either in both cases the error occurs within acceptable limits, or in both cases the error exceeds such limits. Lit.: Voevodin V.V., Computational foundations of linear algebra, M., 1977; Shura-Bura M.R., “Applied mathematics and mechanics,” 1952, vol. 16, no. 5, p. 575-88; Bakhvalov N. S., Numerical methods, 2nd ed., M., 1975; Wilkinson J. X., The Algebraic Eigenvalue Problem, trans. from English, M.. 1970; Bakhvalov N. S., in the book: Computational methods and programming, v. 1, M., 1962, p. 69-79; Godunov S.K., Ryabenkiy V.S., Difference schemes, 2nd ed., M., 1977; Bakhvalov N. S., "Doc. USSR Academy of Sciences", 1955, v. 104, no. 5, p. 683-86; his, "J. will calculate, mathematics and mathematical physics", 1964; vol. 4, no. 3, p. 399-404; Lapshin E. A., ibid., 1971, vol. 11, no. 6, p. 1425-36. N. S. Bakhvalov.
when solving algebraic equations numerically - the total influence of roundings made at individual steps of the computational process on the accuracy of the resulting linear algebraic solution. systems. The most common way to a priori estimate the total impact of rounding errors in numerical methods of linear algebra is the so-called scheme. reverse analysis. In application to solving a system of linear algebraic. equations, the inverse analysis scheme is as follows. The solution calculated by the direct method does not satisfy (1), but can be represented as an exact solution of the perturbed system. The quality of the direct method is assessed by the best a priori estimate, which can be given for the norms of the matrix and vector. Such “best” and so-called. respectively, the matrix and the vector of equivalent perturbation for the method M. If estimates for and are available, then theoretically the error of the approximate solution can be estimated by the inequality Here is the condition number of the matrix A, and the matrix norm in (3) is assumed to be subordinate to the vector norm. In reality, the estimate for is rarely known , and the main meaning of (2) is the ability to compare the quality of different methods. Below is the form of some typical estimates for the matrix For methods with orthogonal transformations and floating point arithmetic (in system (1) A and b are considered real) In this estimate - the relative accuracy of arithmetic. operations in a computer, is the Euclidean matrix norm, f(n) is a function of the form, where n is the order of the system. The exact values of the constant C of the indicator k are determined by such details of the computational process as the method of rounding, the use of the operation of accumulating scalar products, etc. Most often, k = 1 or 3/2. In the case of Gaussian-type methods, the right side of estimate (4) also includes a factor that reflects the possibility of growth of the elements of the Ana matrix at intermediate steps of the method compared to the initial level (such growth is absent in orthogonal methods). To reduce the value, various methods are used to select the leading element, preventing the matrix elements from increasing. For the square root method, which is usually used in the case of a positive definite matrix A, the strongest estimate is obtained. There are direct methods (Jordan, bordering, conjugate gradients), for which direct application of the inverse analysis scheme does not lead to effective estimates. In these cases, when studying N., other considerations are also applied (see -). Lit.: Givens W., "TJ. S. Atomic Energy Commiss. Repts. Ser. OR NL", 1954, No. 1574; Wilkinson J. H., Rounding errors in algebraic processes, L., 1963; Wilkinson D. J.
Stable methods are characterized by an increase in error as The error of such methods is usually assessed as follows. An equation is constructed regarding the disturbance introduced either by rounding or by method errors and then the solution to this equation is examined (see,). In more complex cases, the method of equivalent perturbations is used (see,), developed in relation to the problem of studying the accumulation of computational errors when solving differential equations (see,,). Calculations using a certain calculation scheme with rounding are considered as calculations without rounding, but for an equation with perturbed coefficients. By comparing the solution of the original grid equation with the solution of the equation with perturbed coefficients, an error estimate is obtained. Considerable attention is paid to choosing a method with, if possible, lower values of q and A(h). With a fixed method for solving the problem, the calculation formulas can usually be converted to the form where (see , ). This is especially significant in the case of ordinary differential equations, where the number of steps in some cases turns out to be very large. The value (h) can grow greatly with increasing integration interval. Therefore, they try to use methods with a lower value of A(h) if possible. In the case of the Cauchy problem, the rounding error at each specific step in relation to subsequent steps can be considered as an error in the initial condition. Therefore, the infimum (h) depends on the characteristic of the divergence of close solutions of the differential equation defined by the variational equation. In the case of a numerical solution of an ordinary differential equation, the equation in variations has the form and therefore, when solving a problem on the interval (x 0 , X), one cannot count on the constant A(h) in the majorant estimate of the computational error being significantly better than Therefore, when solving this problem, one-step methods are most commonly used methods of the Runge-Kutta type or methods of the Adams type (see,), where the method is mainly determined by solving the equation in variations. For a number of methods, the main term of the method error accumulates according to a similar law, while the computational error accumulates much faster (see). Area of practice the applicability of such methods turns out to be significantly narrower. The accumulation of computational error significantly depends on the method used to solve the grid problem. For example, when solving grid boundary value problems corresponding to ordinary differential equations using shooting and sweeping methods N. item has the character A(h)h-q, where q is the same. The values of A(h) for these methods may differ so much that in a certain situation one of the methods becomes inapplicable. When solving a grid boundary value problem for Laplace's equation by the shooting method, the problem has the character c 1/h, c>1, and in the case of the sweep method Ah-q. With a probabilistic approach to the study of rounding errors, in some cases they a priori assume some kind of error distribution law (see), in other cases they introduce a measure on the space of the problems under consideration and, based on this measure, obtain a law of rounding error distribution (see, ). With moderate accuracy in solving the problem, majorant and probabilistic approaches to assessing the accumulation of computational error usually give qualitatively the same results: either in both cases the error occurs within acceptable limits, or in both cases the error exceeds such limits. Lit.: Voevodin V.V., Computational foundations of linear algebra, M., 1977; Shura-Bura M.R., “Applied mathematics and mechanics,” 1952, vol. 16, no. 5, p. 575-88; Bakhvalov N. S., Numerical methods, 2nd ed., M., 1975; Wilkinson J. X., The Algebraic Eigenvalue Problem, trans. from English, M.. 1970; Bakhvalov N. S., in the book: Computational methods and programming, v. 1, M., 1962, p. 69-79; Godunov S.K., Ryabenkiy V.S., Difference schemes, 2nd ed., M., 1977; Bakhvalov N. S., "Doc. USSR Academy of Sciences", 1955, v. 104, no. 5, p. 683-86; his, "J. will calculate, mathematics and mathematical physics", 1964; vol. 4, no. 3, p. 399-404; Lapshin E. A., ibid., 1971, vol. 11, no. 6, p. 1425-36. N. S. Bakhvalov.
Accumulation- accumulations, cf. (book). 1. units only Action according to verb. accumulate-accumulate and accumulate-accumulate. water. Initial accumulation of capital (starting point of creation........
Ushakov's Explanatory Dictionary
Accumulation Avg.— 1. Process of action according to meaning. verb: accumulate, accumulate. 2. Status by value. verb: accumulate, accumulate. 3. What has been accumulated.
Explanatory Dictionary by Efremova
Accumulation- -I; Wed
1. to Accumulate - accumulate. N. wealth. N. knowledge. Sources of accumulation.
2. plural only: accumulations. What is accumulated; saving. Increase your savings........
Kuznetsov's Explanatory Dictionary
Accumulation— - 1. increase in personal capital, reserves, property; 2.
share of national
income used to replenish production and non-production funds in........
Economic dictionary
Accumulation- The situation in which it occurs
growth of trading positions created earlier. This usually happens after
by adding newly opened positions to existing ones.........
Economic dictionary
Accumulation Gross— acquisition of goods produced in the reporting period
period, but not consumed.
Index
accounts
Capital transactions of the system of national accounts include........
Economic dictionary
Dividend Accumulation— In life insurance: a settlement method contained in the terms of the life insurance policy, which provides the opportunity to leave the insurance in a deposit account......
Economic dictionary
Accumulation by the Investor of Less than 5% of the Shares of the Company that is the Target of the Repurchase— As soon as 5% of the shares are acquired,
the buyer must provide information to the Securities Commission
papers and
exchanges, to the relevant exchange and to the company,........
Economic dictionary
Accumulation of Fixed Capital Gross— investing in fixed assets (funds) to create new income in the future.
Economic dictionary
Fixed Capital Accumulation, Gross- - investing in
basic
capital (
fixed assets) to create a new
income in the future. V.n.o.c. consists of the following elements: a)
acquisition........
Economic dictionary
Accumulation Insurance— ENDOWMENT INSURANCEA form of life insurance that combines
INSURANCE and compulsory
accumulation. It differs from ordinary life insurance in that after a certain........
Economic dictionary
Accumulation, Accumulation— Corporate financing: profits that are not paid as dividends, but are added to the company's capital stock. See also accumulated profits tax. Investments:........
Economic dictionary
Attraction, Accumulation, Formation of Capital; Increase in Fixed Capital- Creation or expansion by accumulation of savings of capital or means of production (producers goods) - buildings, equipment, machinery - necessary for the production of a number of......
Economic dictionary
Accumulation- - transformation of part of the profit into capital, increase in stocks of materials, property, cash, increase in capital, fixed assets by the state, enterprises,......
Legal dictionary
Accumulation- using part of the income to expand production and increase the output of products and services on this basis. The size of the accumulation and the rate of its growth depend on the volume........
Initial Capital Accumulation- the process of transforming the bulk of small commodity producers (mainly peasants) into hired workers by separating them from the means of production and transforming......
Big encyclopedic Dictionary
Measurement Errors— (measurement errors) - deviations of measurement results from the true values of the measured quantity. Systematic measurement errors are mainly due to........
Large encyclopedic dictionary
Errors of Measuring Instruments— deviations of metrological properties or parameters of measuring instruments from the nominal ones, affecting the errors of measurement results (creating so-called instrumental measurement errors).
Large encyclopedic dictionary
Initial Accumulation— - the process of transforming the bulk of small commodity producers, mainly peasants, into hired workers. Creation of savings by entrepreneurs for subsequent organization........
Historical Dictionary
Initial Accumulation- accumulation of capital that precedes capitalism. method of production, making this method of production historically possible and constituting its starting, initial........
Soviet historical encyclopedia
Gross Fixed Capital Formation- investment by resident units of funds in fixed capital assets to create new income in the future by using them in production. Gross fixed capital formation........
Sociological Dictionary
Measurement Based on Error Indicator- - English measurement, indicator error,-oriented; German Fehlermessung. According to V. Torgerson - a measurement aimed at identifying information about indicators or stimuli in the reactions of respondents......
Sociological Dictionary
Capital Accumulation- - English capital accumulation; German Accumulation. The transformation of surplus value into capital, occurring in the process of expanded reproduction.
Sociological Dictionary
Capital Accumulation Initial- - English capital accumulation, primitive; German Akkumulation, urprungliche. The previous capitalist, the method of production, the process of separating direct producers (chief arr. peasants).......
Sociological Dictionary
Capital Accumulation— (capital accumulation) - see Capital accumulation.
Sociological Dictionary
Accumulation (or Expanded Reproduction) of Capital- (accumulation (or expanded or extended reproduction) of capital) (Marxism) - the process during which capitalism develops through the hiring of labor to produce surplus......
Sociological Dictionary
Initial Accumulation- (primitive accumulation) (Marxism) - the historical process by which capital was accumulated before capitalism appeared. In "Das Kapital" Marx wonders........
Sociological Dictionary
Temporary Accumulation of Waste at the Industrial Site— - storage of waste on the territory of the enterprise in places specially equipped for these purposes until they are used in the subsequent technological cycle or sent......
Ecological dictionary
ACCUMULATION- ACCUMULATION, -i, cf. 1. see save up, -sya. 2. pl. Accumulated amount, amount of something. Large savings. || adj. cumulative, -th, -oe (special). Cumulative statement.
Ozhegov's Explanatory Dictionary
BIOLOGICAL ACCUMULATION— BIOLOGICAL ACCUMULATION concentration (accumulation) of a number of chemical substances (pesticides, heavy metals, radionuclides, etc.) in trophic......
Ecological dictionary















